Why Score Facets?
One typical use case for scoring facets would be for lightning fast recommendations based on market basket co-occurrence. We'll explore this scenario below:
First let's look at the syntax for scoring facets:
scoreNodes(facet(baskets,
q="products:A",
buckets="products",
bucketSorts="count(*) desc",
bucketSizeLimit=50,
count(*)))
Let's breakdown what the expression is doing.
The facet expression calls Solr's JSON facet API and emits tuples which contain the facet results. In this case it is searching the baskets collection. The query is looking for all records in the baskets collection that have product A in the products field.
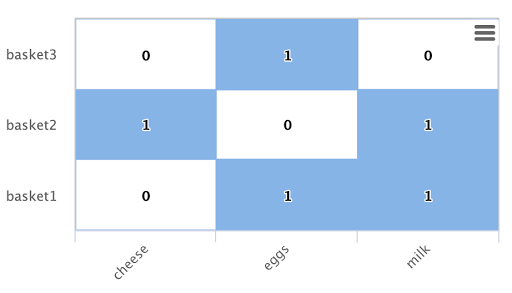
The baskets collection contains a multi-valued field called products which contains all the products in the basket. For example
id products
basket1 [A, B, C]
basket2 [A, C, E]
basket3 [B, C, D]
The sample facet expression will return the following tuples:
products: C
count(*): 2
products: B
count(*): 1
products: E
count(*): 1
Product C is in two baskets with product A. Products B and E are both in one basket with product A.
So it would seem that the most relevant facet/product for product A would be product C.
But, there is something we don't know yet. How often product C occurs in all the baskets. If product C occurs in a large percentage of baskets, then it doesn't have any particular relevance to product A.
This is where the scoreNodes function does it's magic. The scoreNodes function scores the facets based on the raw facet counts and their frequency across the entire collection.
The scoring formula is similar to the tf*idf scoring algorithm used to score results from a full text search. In the full text context tf (term frequency) is the number of times the term appears in the document. idf (inverse document frequency) is computed based on the document frequency of the term, or how many documents the term appears in. The idf is used to provide a boost to terms that are more rare in the index.
scoreNodes uses the same principal to score facets, but the facet count is used as the tf value in the formula. The idf is computed for each facet term based on global statistics across the entire collection. The effect of the scoreNodes algorithm is to provide a boost to facet terms that are rarer in the collection.
The scoreNodes functions adds a field to each facet tuple called nodeScore, which is the relevance score for the facet. You can use the top expression to find the most relevant facet:
top(n=2, sort="nodeScore desc",
scoreNodes(facet(baskets,
q="products:A",
buckets="products",
bucketSorts="count(*) desc",
bucketSizeLimit=50,
count(*)))
The expression above emits the two highest scoring facets based on the nodeScore.